llamaMan
Manager for running multiple llama.cpp inference servers from one container: spawns sibling GPU containers via the Docker socket, Ollama-compatible API proxy with LRU model eviction, clustering, concurrency gating, and multi-vendor GPU monitoring.
Docker
JavaScript
llama.cpp
Python
Features
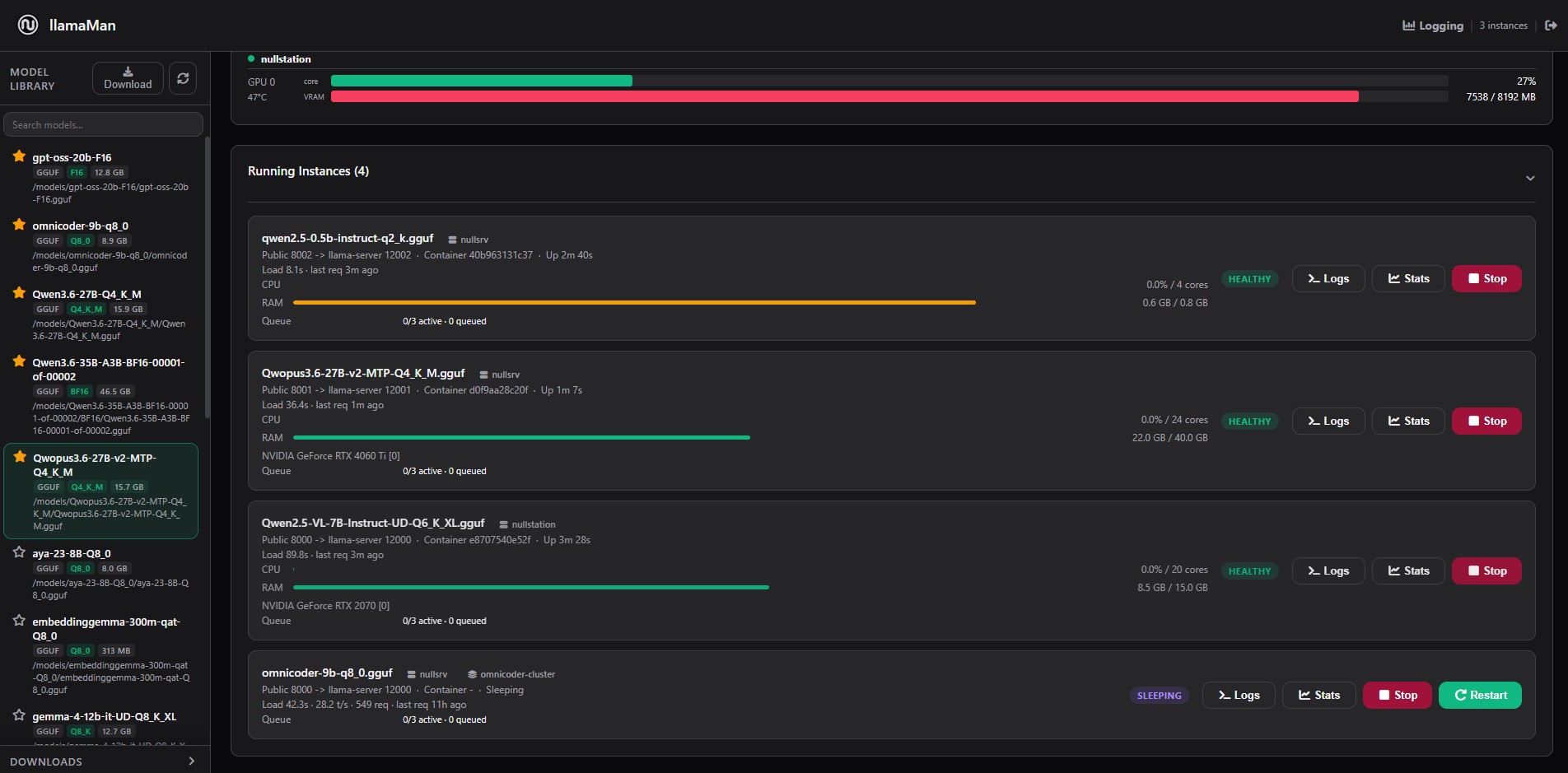
Flexibility and Scaling
- Launch and manage multiple llama.cpp server instances from a browser dashboard.
- Cluster multiple llamaMan instances across your network.
- Run models in isolated Docker containers with configurable GPU layers, context size, CPU threads, memory limits, parallel slots, GPU selection, and extra server flags.
- Use LlamaMan as a drop-in Ollama-compatible backend for Open WebUI and other Ollama clients.
- Serve OpenAI-compatible chat completions, model listings, and embeddings from local GGUF models.
- Auto-start models on demand when requests arrive, using saved presets or sensible defaults.
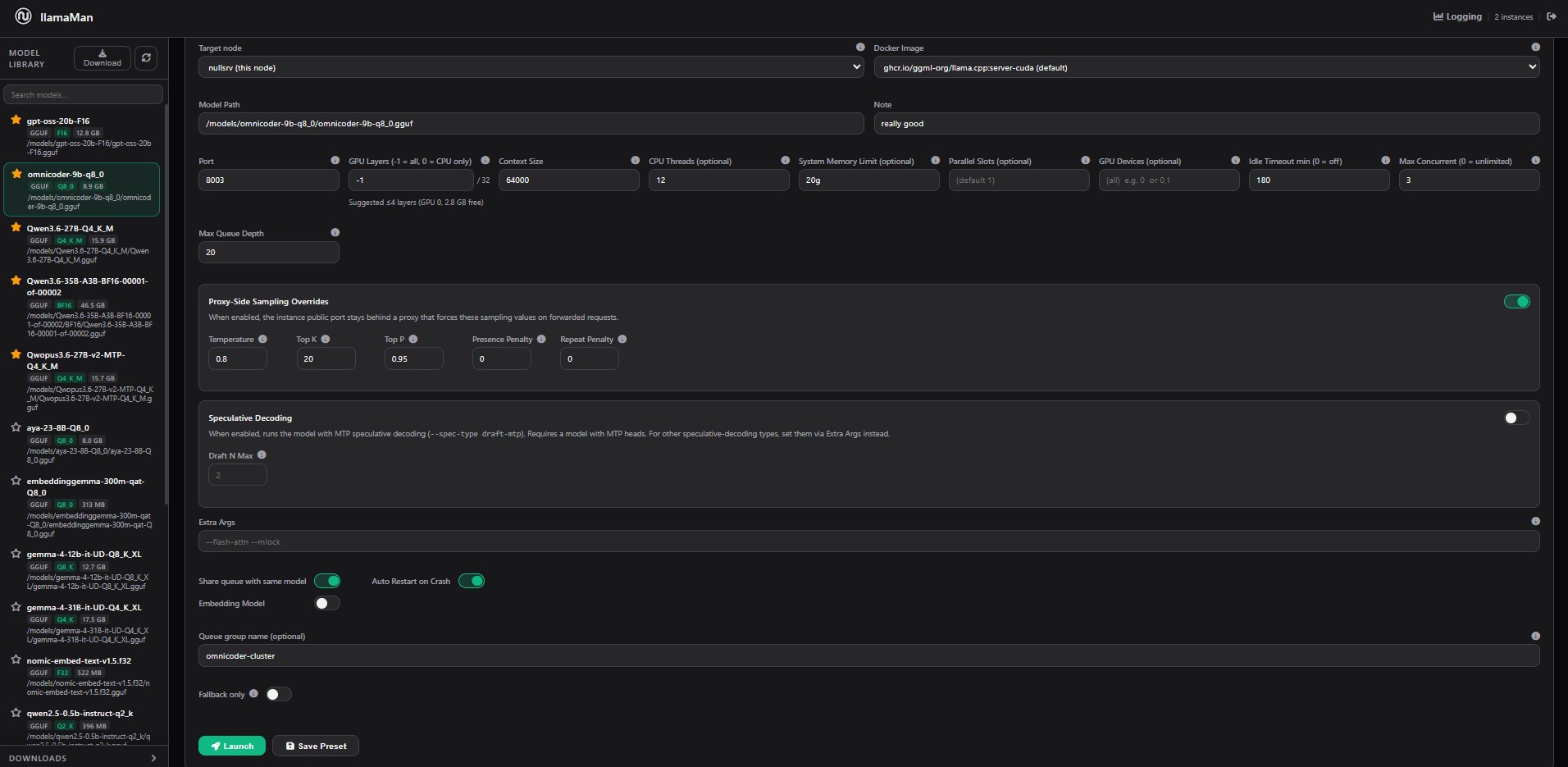
Resource Management
- Keep GPU memory under control with idle sleep, wake-on-request, and configurable model eviction limits.
- Save per-model launch presets, notes, favorites, and proxy-side sampling overrides for convenience and 2-click deployments.
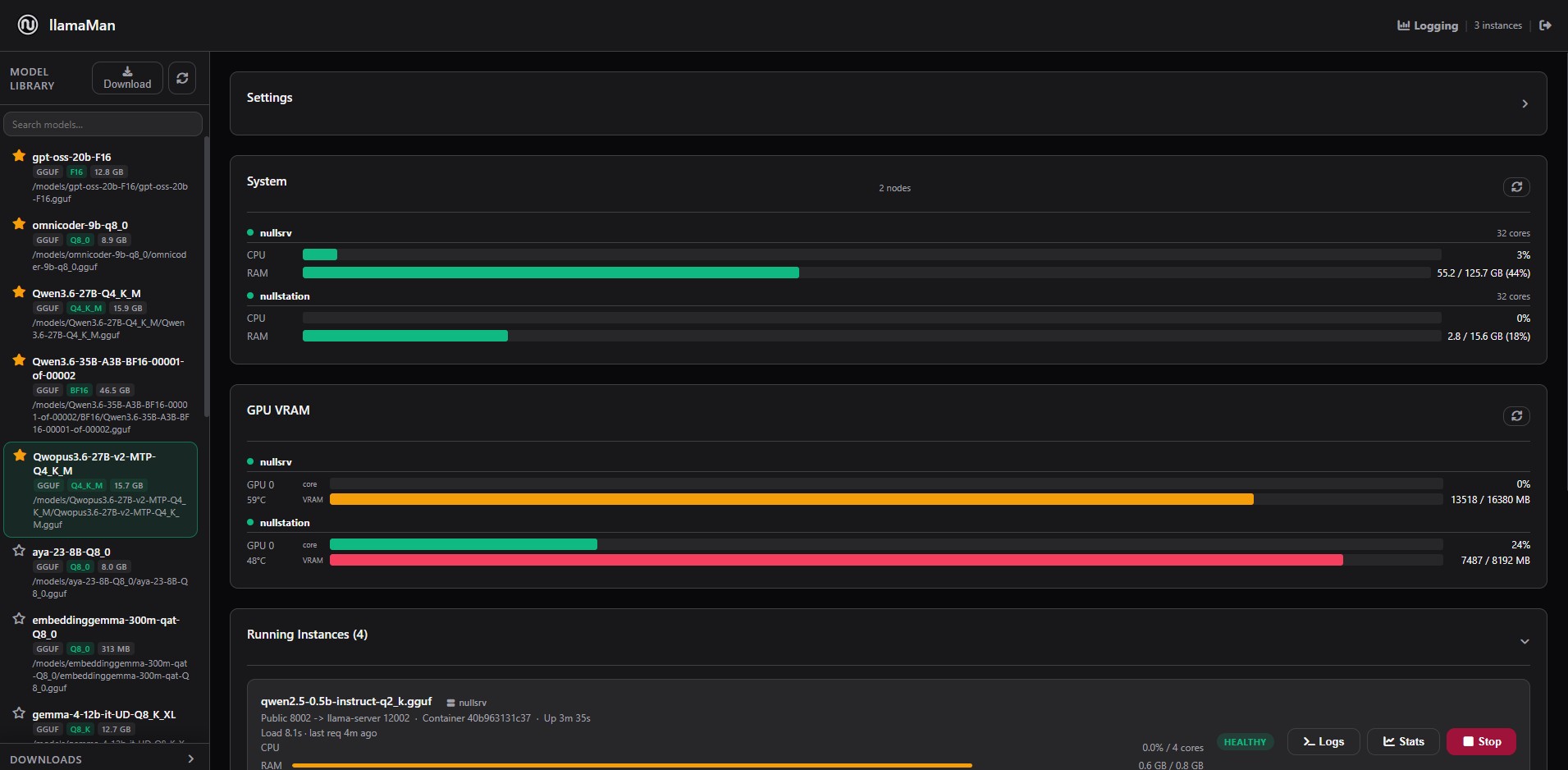
Monitoring
- Monitor every running model with live status, logs, load time, tokens per second, time to first token, request counts, CPU/RAM usage, and GPU assignment.
- View native GPU telemetry for NVIDIA, AMD, and Intel Arc, including VRAM, utilization, and temperature.
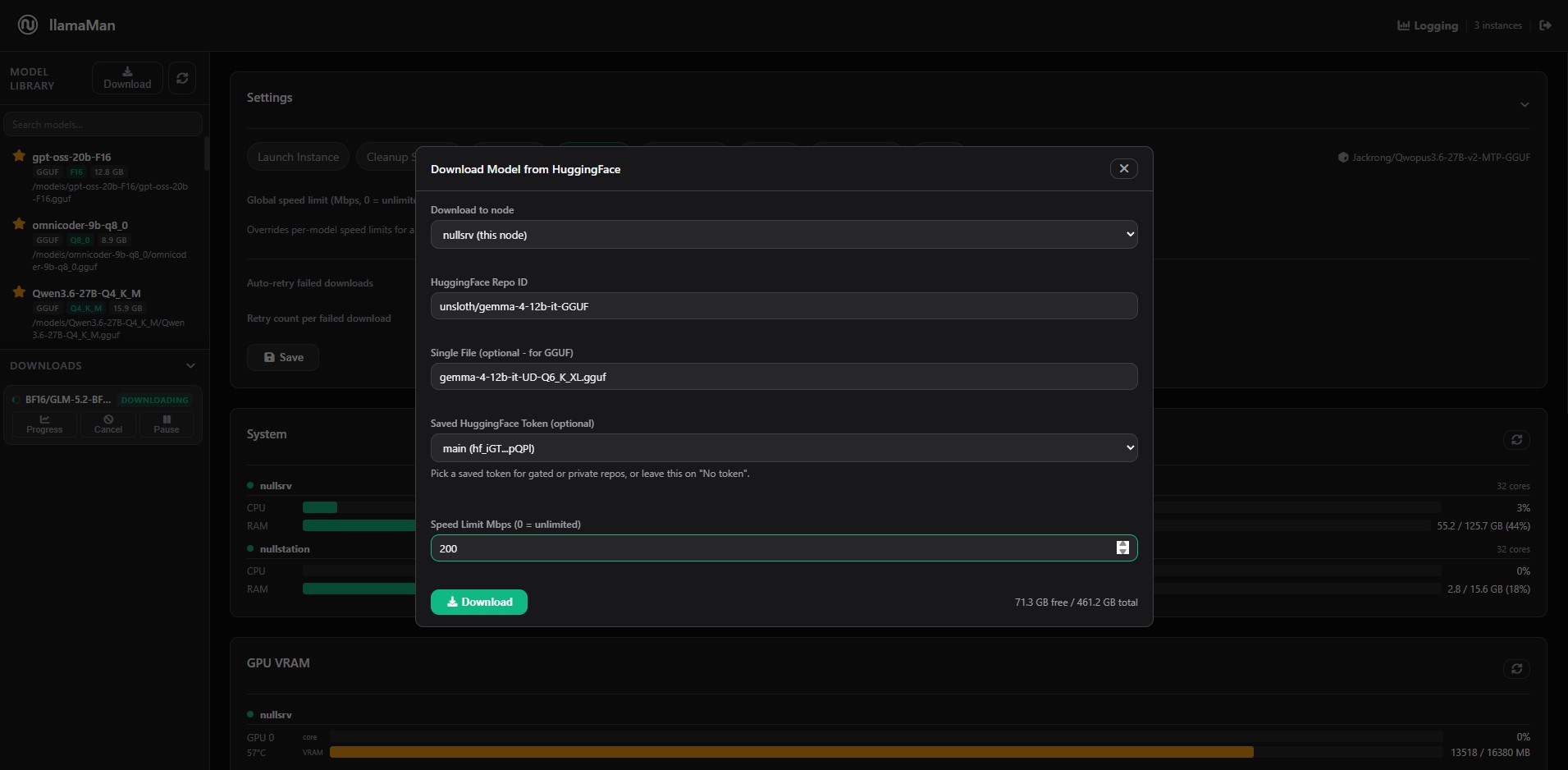
Downloads
- Download GGUF models directly from Hugging Face with progress tracking, pause/resume, retry, cancellation, saved tokens, and per-download speed limits.
- Global downloads throttling.
- Download models based on settings from other cluster nodes.
Security
- Protect the dashboard and model APIs with first-run admin setup and session login.
- API keys support, and optional bearer-token enforcement for all serving endpoints.